데이터의 무결성은 데이터의 정확성, 일관성, 유효성이 유지되는 것을 말한다. 데이터의 무결성을 유지하는 것은 데이터베이스 관리시스템 (DBMS)의 중요한 기능이며, 주로 데이터에 적용되는 연산에 제한을 두어 데이터의 무결성을 유지한다. 데이터베이스에서 말하는 무결성에는 다음과 같은 4가지 종류가 있다.
1) 개체 무결성 (Entity integrity)
모든 테이블이 기본 키 (primary key)로 선택된 필드 (column)를 가져야 한다. 기본 키로 선택된 필드는 고유한 값을 가져야 하며, 빈 값은 허용하지 않는다.
2) 참조 무결성 (Referential integrity)

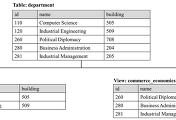
[그림 1] 참조 무결성의 예시
참조 무결성에 대한 예시는 [그림 1]에서 설명한 것 이외에도 더 많은 것들이 있다. 참조 무결성에 대한 더욱 자세한 사항은 이 글의 다음 부분에 있는 외래 키 (foreign key) 항목에서 더욱 자세하게 설명할 것이다.
3) 도메인 무결성 (Domain integrity)
도메인 무결성은 테이블에 존재하는 필드의 무결성을 보장하기 위한 것으로 필드의 타입, NULL값의 허용 등에 대한 사항을 정의하고, 올바른 데이터의 입력 되었는지를 확인하는 것이다. 예를 들어, 주민등록번호 필드에 알파벳이 입력되는 경우는 도메인 무결성이 깨지는 경우라고 볼 수 있다. DBMS의 기본값 설정, NOT NULL 옵션 등의 제약 사항으로 도메인 무결성을 보장할 수 있다.
4) 무결성 규칙 (Integrity rule)
데이터베이스에서 무결성 규칙은 데이터의 무결성을 지키기 위한 모든 제약 사항들을 말한다. 비즈니스 규칙 (business rule)은 데이터베이스를 이용하는 각각의 유저에 따라 서로 다르게 적용되지만, 무결성 규칙은 데이터베이스 전체에 공통적으로 적용되는 규칙이다.
데이터베이스를 공부하다 보면 테이블과 레코드, 필드 다음으로 많이 접하는 단어는 아마도 기본 키, 외래 키와 같은 키 (key)일 것이다. 이러한 종류의 키들은 데이터베이스에서 데이터의 무결성을 유지하기 위한 중요한 수단으로 이용되고 있다. DBMS에서 이용하는 키에서는 여러 종류가 있으며, 각각에 대한 자세한 사항은 다음과 같다.
1) 슈퍼 키 (Super key)
슈퍼 키는 테이블에 존재하는 필드들의 부분집합으로써, 유일성을 만족해야 한다. 위의 [그림 1]의 student 테이블의 id 필드는 슈퍼 키가 될 수 있으며, 전체 필드의 부분집합인 { id, dept_id } 또한 레코드를 유일하게 구별할 수 있는 식별자이기 때문에 슈퍼키가 될 수 있다. 아래에서 설명할 후보 키 (candidate key)는 슈퍼 키 중에서 최소성 (irreducibility)을 만족하는 키와 같다.
후보 키는 이름에서도 나타나듯이 기본 키가 될 수 있는 후보를 말한다. 후보 키는 테이블에 존재하는 전체 필드의 부분집합으로써, 유일성 (uniqueness)과 최소성 (irreducibility)을 만족해야 한다. 유일성은 모든 레코드에서 해당 필드에 중복된 값이 나타나지 않는다는 속성이며, 최소성은 최소한의 필드로 레코드를 유일하게 구별할 수 있어야 한다는 속성이다.
위의 [그림 1]의 student 테이블의 dept_id는 중복된 값을 가질 수 있기 때문에 유일성을 만족하지 않기 때문에 후보 키가 될 수 없다. 또한, student 테이블의 id 필드만으로도 레코드를 유일하게 구별할 수 있기 때문에 { id, dept_id }로 이루어진 부분 집합은 최소성을 만족하지 않으므로 후보 키가 될 수 없다.
3) 기본 키 (Primary key)
기본 키는 테이블에서 특정 레코드를 구별하기 위해 후보 키 중에서 선택된 고유한 식별자를 말한다. 기본 키는 후보 키와 같이 유일성과 최소성에 대한 속성을 가져야 하며, NULL값을 가질 수 없다. 기본 키를 설정할 때는 아래와 같은 두 가지 사항을 고려하는 것이 좋다.
값이 자주 변경되지 않는 것을 선택: 기본 키로 선택된 필드는 값이 변경될 때마다 해당 값이 유일한지, NULL값은 아닌지를 검사해야 하기 때문에 값이 자주 변경되지 않는 필드를 기본 키로 설정하는 것이 바람직하다.
값이 단순한 것을 선택: 기본 키로 선택된 필드에 저장되는 데이터가 많은 자릿수를 갖는 정수거나 많은 문자를 포함하는 문자열이라면, 기본 키를 비교할 때 그만큼 많은 비용이 소모될 것이다. 그러므로, 짧고 단순한 형식의 데이터를 저장하는 필드를 기본 키로 설정하는 것이 DBMS의 성능 측면에서 유리하다.
후보 키 중에서 기본 키로 선택된 것들을 제외한 모든 키를 대체 키라고 한다.
5) 복합 키 (Composite key)
한 개 이상의 필드를 포함하는 키를 복합 키라고 한다. 앞에서 예를 들은 { id, dept_id }와 같은 키는 복합 키의 한 예시이다.
6) 외래 키 (Foreign key)
외래 키는 한 테이블의 키 중에서 다른 테이블의 레코드를 유일하게 식별할 수 있는 키를 말한다. 외래 키는 한 테이블의 레코드에서 다른 테이블의 레코드를 참조하기 위해 이용된다. 아래의 [그림 2]는 product 테이블을 참조하는 order 테이블을 보여준다. 그림에 있는 order 테이블의 product_id 필드는 product 테이블의 레코드를 참조하기 위해 설정된 외래 키이다.

[그림 2] 외래 키를 이용한 테이블 간의 참조 관계
외래 키는 아래와 같은 속성들을 갖는다.
- 하나의 필드 또는 전체 필드의 부분집합으로 구성된다.
- 중복된 값과 NULL값을 가질 수 있다.
- 반드시 참조되는 테이블에서 유일한 값을 갖는 필드를 참조해야 한다. 예를 들어, 외래 키는 참조되는 테이블의 기본 키를 참조할 수도 있다.
- 참조되는 테이블에 존재하는 값만을 가져야 한다. NULL값은 실제로 존재하는 값은 아니지만, 많은 데이터베이스에서 NULL값은 예외로 한다.
참조 관계에 있는 테이블 사이에서는 위에서 설명한 참조 무결성과 관계된 문제가 발생할 수 있다. 외래 키는 위와 같은 제약 조건을 통해 참조 무결성과 관련된 문제가 발생하지 않도록 한다.
데이터베이스에서는 참조 무결성을 위해 참조 대상이 존재하지 않는 외래 키를 허용하지 않는다. 즉, 어떠한 외래 키 $B$가 $A$를 참조한다면, $A$는 반드시 데이터베이스에 존재해야 한다. 외래 키는 참조 무결성을 지키기 위해 RESTRICTED와 CASCADE, SET NULL이라는 개념을 외래 키에 적용할 수 있도록 기능을 제공한다. 각 개념들의 동작은 아래와 같다.
- RESTRICTED: 레코드를 변경 또는 삭제하고자 할 때 해당 레코드를 참조하고 있는 개체가 있다면, 변경 또는 삭제 연산을 취소한다.
- CASCADE: 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체도 변경 또는 삭제된다.
- SET NULL: 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체의 값을 NULL로 설정한다.
'데이터베이스' 카테고리의 다른 글
| [관계형 데이터베이스] - ER 다이어그램 (Entity-Relationship Diagram) (0) | 2016.12.10 |
|---|---|
| [관계형 데이터베이스] - 데이터베이스 정규화 (Database Normalization) (1) | 2016.12.09 |
| [관계형 데이터베이스] - ER 모델 (Entity-Relationship Model) (0) | 2016.12.07 |
| [관계형 데이터베이스] - 함수 종속성 (Functional Dependency) (1) | 2016.11.13 |
| [관계형 데이터베이스] - 데이터베이스와 뷰 (1) | 2016.11.13 |