
머신 러닝 분야의 엄청난 발전과 함께 최근 머신 러닝을 활용하면 무엇이든지 가능한 것처럼 이야기하는 연구나 제품들이 많이 등장하고 있다. 그러나 머신 러닝은 장단점이 존재하며, 실제 머신 러닝을 실용 기술 개발 단계에서 적용하다보면 기존의 방법론보다 비효율적인 경우도 많이 접하게 된다. 머신 러닝의 장단점과 응용 가능 분야를 이해하기 위해, 이 글에서는 머신 러닝이 무엇이고 어떠한 점이 새로운 것인지 다양한 관점에서 소개한다.
머신 러닝을 한 문장으로 정의하자면 '데이터로부터 예측 알고리즘을 학습시키기 위한 모든 구성 요소'이다. 즉, 머신 러닝의 가장 기본적인 요소 중 하나는 '데이터'이다. 컴퓨터 과학에서 데이터를 기반으로 연산을 수행하는 모든 것을 데이터 과학이라고 정의할 수 있으며, 인공지능, 머신 러닝, 딥 러닝 등과 같이 혼용하여 사용되고 있는 용어들은 아래와 같이 정리할 수 있다.
- 데이터 과학 (Data science): 데이터의 수집, 저장, 분석 등을 포함하는 모든 분야.
- 인공지능 (Artificial Intelligence): 통계 및 알고리즘 등을 이용하여 데이터 분석을 자동화하는 분야.
- 머신 러닝 (Machine Learning): 주어진 데이터를 기반으로 데이터 분석을 자동화하는 분야.
- 딥 러닝 (Deep Learning): 주어진 데이터와 심층 인공신경망을 이용하여 데이터 분석을 자동화하는 분야.
데이터 분석을 자동화한다는 것은 어떠한 데이터가 입력되었을 때 사람이 결정한 분석 방법에 의해 데이터가 처리되는 것이 아니라, 알고리즘이 자동으로 적합한 데이터 분석 방법을 결정하여 입력 데이터를 처리하는 것을 의미한다. 딥 러닝은 자동화된 데이터 분석 알고리즘으로 심층 인공신경망 (deep neural networks)를 사용하는 방법론을 말한다. 따라서 데이터 과학, 인공지능, 머신 러닝, 딥 러닝은 아래의 그림 1과같은 계층 구조 및 포함 관계를 갖는다.

머신 러닝의 목표가 데이터 분석을 자동화하는 것이지만, 이를 위해서는 대부분의 경우에 학습 데이터가 반드시 필요하다. 자연어처리와 같은 분야를 기반으로 학습 데이터 수집을 자동화하기 위한 연구가 진행되고는 있지만, 아직도 데이터 수집 과정의 대부분에는 사람의 노동력이 필요한 경우가 많다. 따라서, 머신 러닝을 어떠한 응용에 적용할 때는 해당 응용에 대한 학습 데이터를 효율적으로 수집할 수 있는지를 반드시 확인해야한다.
어떠한 의사결정 시스템을 개발하는 컴퓨터 과학자의 고전적인 역할은 아래의 3가지 과정으로 구성될 수 있으며, 이러한 과정을 반복함으로써 더 좋은 의사결정 시스템을 개발할 수 있었다. 그림 2는 의사결정 시스템을 개발하기 위한 고전적인 과정을 나타낸다.
- 효과적인 의사결정 규칙 고안 및 알고리즘 형태의 구현을 위한 프로그래밍.
- 알고리즘에 의해 계산된 예측 및 의사결정으로부터 오차를 분석.
- 분석된 오차를 기반으로 새로운 의사결정 규칙 고안 및 프로그래밍.

그러나 머신 러닝 기반의 의사결정 시스템 개발에서는 그림 3과 같이 컴퓨터 과학자의 역할이 학습 데이터 처리 및 프로그래밍으로 변경되고, 시스템의 핵심이 되는 의사결정 규칙의 고안은 머신 러닝 알고리즘이 담당하게된다.
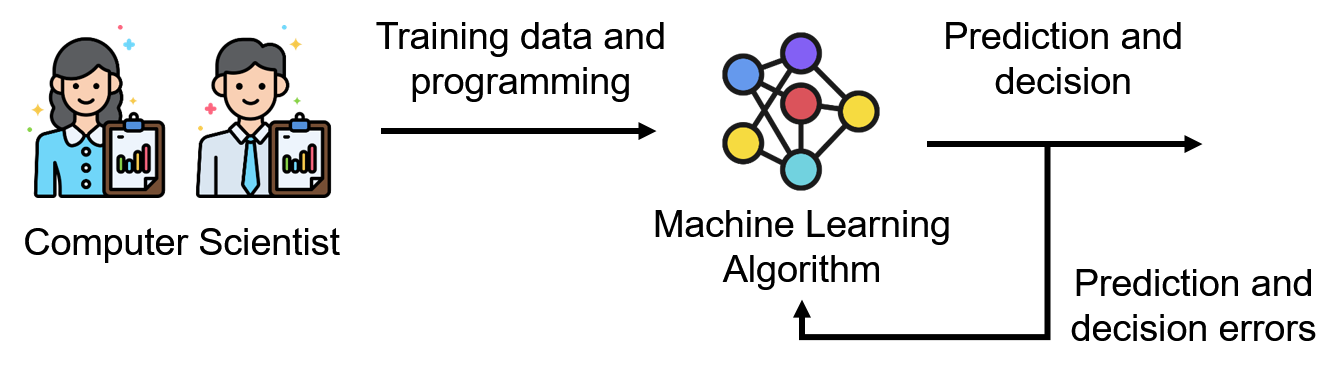
기존에는 예측 및 의사결정 오차를 사람이 직접 분석하여 새로운 규칙을 정의했다면, 머신 러닝에서는 오차로부터 머신 러닝 알고리즘이 자동으로 오차를 최소화하기 위한 새로운 규칙을 만든다. 따라서, 알고리즘 관점에서 머신 러닝은 알고리즘을 만드는 알고리즘으로 이해할 수 있다. 그러나 머신 러닝 알고리즘의 복잡도에 따라 만들어낼 수 있는 알고리즘의 범위가 제한되며, 너무 복잡한 머신 러닝 알고리즘을 이용할 경우에는 과적합 (overfitting)이라는 문제가 발생할 수도 있다. 따라서, 머신 러닝을 응용 개발에 활용하기 위해서는 머신 러닝에 대한 이해를 바탕으로 적합한 알고리즘과 hyperparameter를 설정해줄 수 있어야한다.
머신 러닝 알고리즘은 입력 공간 $\mathcal{X}$를 출력 공간 $\mathcal{Y}$로 사상하는 함수 $f: \mathcal{X} \rightarrow \mathcal{Y}$로 이해될 수 있다. 이러한 정의에서 입력 공간은 물체의 사진, 화학적 성분, 유전 정보 등의 입력 데이터를 포함하는 공간이며, 이에 상응하는 출력 공간은 물체의 종류, 화학적 성질, 유전자 발현 등과 같은 출력 데이터를 포함하는 공간이다. 따라서, 머신 러닝 알고리즘의 동작은 주어진 입력 $\textbf{x}\in\mathcal{X}$로 부터 출력 $\textbf{y}\in\mathcal{Y}$를 생성하는 $\textbf{y} = f(\textbf{x};\boldsymbol{\theta})$로 정의된다. 이 때, $\boldsymbol{\theta}$는 함수의 형태를 결정하는 매개변수이며, 학습 데이터로부터 최적화되어야 한다. 따라서, 머신 러닝이라는 것은 학습 데이터셋 $\mathcal{D} = \{(\textbf{x}_1,\textbf{y}_1), ..., (\textbf{x}_N, \textbf{y}_N) \}$에 대해 아래의 식 (1)로 정의될 수 있다.
$$ \boldsymbol{\theta}^* = \underset{\boldsymbol{\theta}}{\arg\min} \sum_{(\textbf{x},\textbf{y})\in\mathcal{D}} L(\textbf{y}, f(\textbf{x};\boldsymbol{\theta})) \tag{1}$$
위의 식에서 $L: \mathbb{R} \times \mathbb{R} \rightarrow \mathbb{R}$은 타겟값 $\textbf{y}$와 예측값 $\textbf{y}^{'} = f(\textbf{x};\boldsymbol{\theta})$의 차이를 정량화하는 손실 함수 (loss function)이다.
함수 관점에서 머신 러닝 알고리즘은 $\mathcal{X}$를 $\mathcal{Y}$로 사상하기 위한 함수이며, 학습 알고리즘은 학습 데이터셋 $\mathcal{D}$를 기반으로 함수의 매개변수 $\boldsymbol{\theta}$를 추정하기 위한 최적화 알고리즘이다. 비교적 최근에 연구된 딥 러닝 (deep learning)은 머신 러닝 알고리즘이 어떠한 종류의 함수도 근사할 수 있도록, 막대한 양의 매개변수를 이용하고 이를 최적화하기 위한 방법론이라고 볼 수 있다.