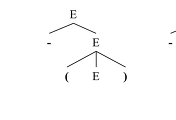
상향식 파싱은 트리의 가장 아래쪽에 위치한 leaf node에서 시작하여 트리의 최상단인 root node쪽으로 진행하면서 파싱을 수행하는 방법이다 [그릠 1]. 상향식 파싱에는 이동-감축 파싱 (shift-reduce parsing)이라고 하는 상향식 파싱의 일반적인 유형이 있으며, 하향식 파싱을 위한 LL 문법과 같이 상향식 파싱을 위한 LR 문법이 있다. 상향식 파싱은 완성된 파스 트리 (parse tree)의 관점에서 볼 때, 가장 우측의 nonterminal 부터 유도 (derivation)가 이루어지기 때문에 입력 문자열에 대한 최우단 유도 (rightmost derivation)을 찾는 것과 같다.

[그릠 1] 상향식 파싱 (bottom-up parsing)을 통한 파스 트리 (parse tree)의 생성
상향식 파싱은 일반적인 트리 형태의 자료구조를 형성하는 것과 반대의 방향으로 파스 트리를 형성한다. 이러한 점은 상향식 파싱을 이해하거나 구현하는데 다소 어려움을 느끼게 한다. 그러나 상향식 파싱은 하향식 파싱의 단점을 보완할 수 있고, 성능 또한 더욱 좋기 때문에 컴파일러에 가장 많이 이용되고 있는 파싱 방법이다.
이동-감축 파서는 (shift-reduce parser) 이름에서도 나타나듯이 이동 (shift)와 감축 (reduce)이라는 두 연산을 이용하여 파싱을 수행한다. 이동-감축 파서에서 가장 중요한 것은 언제 감축을 수행할 것인지와 어떤 생성규칙을 적용할 것인지에 대한 결정이다.
1) 감축 (reducing)
상향식 파싱은 [그림 1]에서도 나타나듯이 입력 문자열을 nonterminal로 감축해가면서 파싱을 수행한다. 이 때, 감축의 대상이 되는 문자열 또는 단일 기호를 핸들 (handle)이라고 한다. 핸들은 반드시 한 생성규칙과 매칭되어야 한다. [그림 1]의 상향식 파싱 과정을 핸들을 이용하여 표현하면 아래의 [그림 2]와 같다.

[그림 2] 입력 문자열 ( id )에 대한 파싱 과정에서의 핸들
중요한 점은 문법이 모호하지 않다면, 파싱 대상 문자열에는 언제나 한 개의 핸들만 존재한다는 것이다.
2) 이동-감축 파서의 연산
이동-감축 파서는 아래와 같이 총 4가지의 연산을 수행할 수 있다.
- 이동 (shift): 다음 입력 기호로 이동
- 감축 (reduce): 핸들이 되는 문자열을 어떠한 nonterminal로 대체할 것인지를 결정
- 수락 (accept): 파싱이 성공했음을 알림
- 오류 (error): 구문 오류를 발견했음을 알리고, 오류 복구 루틴을 호출하거나 파싱을 중단
3) 이동-감축 파서의 구현
이동-감축 파서는 일반적으로 스택을 이용하여 구현된다. 이동-감축 파서는 이동 연산 시, 입력 문자의 한 기호를 스택에 push하고, 감축 연산은 항상 스택의 최상위 부분에서만 수행한다. 아래의 [그림 3]은 [그림 1]의 상향식 파싱 과정을 이동-감축 파서를 통해 나타낸 것이다. [그림 3]의 기호 $는 스택이나 입력 문자열의 끝을 나타낸다.

[그림 3] 이동-감축 파서의 파싱 과정
4) 파싱 과정에서의 충돌
이동-감축 파서에서는 이동/감축 충돌 (shift/reduce conflict)과 감축/감축 충돌 (reduce/reduce conflict)이라는 두 가지 충돌이 발생한다. 이동-감축 파서는 이동과 감축이라는 두 연산을 이용하여 파싱을 수행한다. 그러나 파싱 과정에서 어떠한 연산을 적용해야 하는지 명확하게 결정할 수 없는 상황이 발생할 수 있는데, 이를 충돌이라고 한다. 예를 들어, [그림 3]의 과정 2에서는 terminal id를 감축할 것인지, 입력 문자열에서 terminal )를 스택으로 이동시킬 것인지를 결정해야 한다. 이러한 충돌을 이동/감축 충돌이라고 한다.
감축/감축 충돌은 아래와 같은 문법에서 발생할 수 있다.

이러한 문법에서 만약 이동-감축 파서에 id ( id, id )로 구성된 문자열이 입력되면, 스택에 "id ( id" 가 입력된 상황에서 파서는 id를 생성규칙 (4)를 이용하여 감축할 것인지, 생성규칙 (6)을 이용하여 감축할 것인지를 결정할 수 없다. 이러한 감축/감축 충돌을 제거하는 한 가지 방법은 생성규칙 (1)을 아래와 같이 변형하고, 어휘 분석기에서 함수의 식별자는 $funcId$라는 토큰으로 반환하도록 구성하는 것이다.

생성규칙 (1)을 위와 같이 변형하면, 스택에 "id ( id"가 입력된 경우에는 생성규칙 (6)을 적용하고, 스택에 "funcId ( id"가 입력된 경우에는 생성규칙 (4)를 적용한다.
상향식 파싱의 한 종류인 LR 파싱은 LR 문법을 따르는 문법을 파싱할 수 있는 방법이다. LR 파싱에서 L은 left scanning을, R은 rightmost derivation을 의미한다. LR 파싱은 가장 보편적으로 이용되는 상향식 파싱이다. LR 파싱은 아래와 같은 강점을 갖는다.
- LR 파서는 문맥 자유 문법 (context-free grammar, CFG)으로 작성된 대부분의 프로그래밍 언어 구조를 이해할 수 있다. 또한, LR 문법을 따르지 않는 문맥 자유 문법에 대해서는 일반적으로 충돌을 회피하는 방법들이 있다.
- LR 문법은 예측 또는 LL 파싱으로 이해할 수 있는 문법 유형의 진 상위집합 (proper superset)이다. 따라서, LR 파서는 LL 파서보다 더 많은 종류의 문법을 이해할 수 있다.
- 일반적으로, LR 파서는 예측 및 LL 파서 등에 비해 효율적으로 파싱을 수행할 수 있다.
위와 같은 이점에도 불구하고, LR 파서는 직접 구현하기에 너무 많은 작업을 필요로 한다는 단점이 있다. 이러한 문제점을 해결하기 위해 많은 LR 파서 생성 도구들이 개발되었으며, 그 중에서도 GPL 라이센스를 기반으로 무료로 배포되는 Yacc (Yet Another Compiler Compiler)이 가장 많이 이용되고 있다.
LR 파서 중에서도 가장 일반적으로 이용되는 LR(1) 파서는 LL(1) 파서처럼 파싱 테이블을 생성하여 파싱을 수행한다 [그림 4].

[그림 4] LR(1) 파서의 구조
LR 파서는 $CLOSURE$와 $GOTO$라는 함수를 이용하여 LR 문법으로 작성된 언어에 대한 모든 상태를 기술하는 오토마타 (automata)를 정의하고, 이를 기반으로 파싱 테이블을 생성한다. LR(1) 파서의 파싱 테이블 생성 과정은 너무 복잡하고, 그 내용이 많기 때문에 이 글에서는 따로 서술하지 않는다.
'프로그래밍 언어' 카테고리의 다른 글
| 2018년 6월 최신 프로그래밍 언어 순위 (0) | 2018.06.18 |
|---|---|
| 2018년 프로그래밍 언어 순위 및 비교 (0) | 2018.05.01 |
| [컴파일러] - 구문 분석 (Syntax Analysis) II (0) | 2016.08.21 |
| [컴파일러] - 구문 분석 (Syntax Analysis) I (0) | 2016.08.20 |
| 2016년 1~2월 프로그래밍 언어 순위 및 순위표별 특징 (0) | 2016.02.23 |