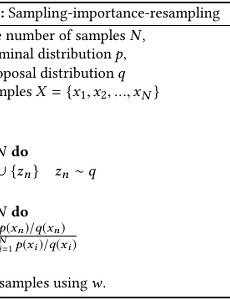전체 글149 [머신 러닝] 중요도 샘플링 (Importance Sampling)과 기댓값 추정 1. 중요도 샘플링 (Importance Sampling) 통계 및 머신러닝 방법론을 공부하다보면 어떠한 확률분포 $p(\textbf{x})$를 따르는 확률변수 $\textbf{x}$에 대해 함수 $f(\textbf{x})$의 기댓값 (expected value)을 구하는 경우를 많이 접한다. 중요도 샘플링은 샘플 $\textbf{x}$에 대한 확률 $p(\textbf{x})$은 쉽게 계산할 수 있지만, $p(\textbf{x})$에서 샘플을 생성하는 것은 어려울 때 사용하는 방법이다. 먼저 $p(\textbf{x})$에 대한 $f(\textbf{x})$의 기댓값은 아래와 같이 정의된다. $$\begin{equation} E_{p(\textbf{x})} [f(\textbf{x})] = \int f(\te.. 2018. 4. 8. [머신 러닝] 기각 샘플링 (Rejection Sampling) Rejection sampling (또는 acceptance-rejection method)은 어떠한 주어진 확률 분포에서 효율적으로 샘플을 생성하기 위해 많이 이용되는 알고리즘이다. 우리가 샘플을 추출하고자 하는 확률 분포 $p$에 대해 아래의 조건이 만족될 때, rejection sampling은 매우 효율적으로 이용될 수 있다. 주어진 확률 분포 $p$의 확률 밀도 함수 (probability density function, PDF)를 알고 있어야 한다.그러나 $p$에서 직접 샘플을 생성하는 것은 매우 어렵거나 불가능하다.따라서, rejection sampling은 확률 밀도 함수를 알고는 있지만, 그 함수를 통해 샘플을 생성하기가 어려울 때 활용할 수 있는 알고리즘이다. 1. 제안 분포 (Prop.. 2018. 4. 8. [데이터 마이닝] K-평균 군집화 (K-means Clustering)와 거리 기반 클러스터링 1. 알고리즘 정의 K-means clustering은 데이터를 입력받아 이를 소수의 그룹으로 묶는 알고리즘이다. 이 알고리즘은 아래의 [그림 1]처럼 label이 없는 데이터를 입력받아 각 데이터에 label을 할당함으로써 군집화를 수행한다. K-means clustering은 개념과 구현이 매우 간단한 기본적인 clustering 알고리즘이면서도 실행 속도가 빠르고, 특정한 형태의 데이터에 대해서는 매우 좋은 성능을 보여주기 때문에 많이 이용되고 있다. [그림 1] K-means clustering의 동작 K-means clustering은 벡터의 형태로 표현된 $N$개의 데이터 $X = \{x_1, x_,2, ..., x_N\}$에 대하여 데이터가 속한 cluster의 중심과 데이터 간의 거리의 차.. 2018. 4. 5. [관계형 데이터베이스] - 동시성 (Concurrency) 1. 데이터베이스에서의 동시성 데이터베이스는 다수의 사용자들이 동시에 접근하는 경우가 빈번하게 발생한다. 그러나 여러 사용자가 동시에 데이터베이스에 접근하는 상황에서 사용자들에 대한 적절한 통제가 이루어지지 않는다면, 데이터베이스의 무결성이 깨지고, 어떠한 transaction의 수행에 대해 의도하지 않은 결과가 반환될 수도 있다.DBMS (Database Management System)는 동시성 제어 (concurrency control)라는 기능을 제공하여 데이터베이스의 무결성을 보호하고, transaction이 항상 정확하고 일관된 데이터를 참조할 수 있도록 해야 한다. 2. 직렬성 (Serializability)과 동시성 (Concurrency) 데이터베이스에서 직렬성 (serializabili.. 2016. 12. 17. [관계형 데이터베이스] - 데이터베이스 복구 1. 데이터베이스 실패 데이터베이스에서 데이터를 저장하는 것만큼 중요한 것은 저장된 데이터를 유지하는 것이다. 데이터베이스는 데이터베이스의 연산 (쿼리문)을 실행하는 동안 하드웨어, 소프트웨어, 외부의 물리적 충격 등으로 인해 시스템의 비정상적인 종료가 발생할 수 있다. 따라서, 이러한 비정상적인 종료에 대비하여 데이터베이스를 복구하기 위한 전략을 구현하는 것이 필요하다. 2. Transaction 단위의 데이터베이스 복구 전략 데이터베이스를 복구하기 위한 전략 중 하나는 transaction을 이용하는 것이다. 데이터베이스에서 transaction은 다수의 쿼리문으로 이루어진 논리적 작업 단위를 말한다. Transaction은 논리적 작업 단위를 구성하는 각 쿼리문의 실행마다 쿼리문의 내용을 데이터베이.. 2016. 12. 16. [관계형 데이터베이스] - ER 다이어그램 (Entity-Relationship Diagram) 1. 개요 ER 다이어그램은 ER 모델 (Entity-Relationship Model)을 기반으로 데이터베이스의 논리적 구조를 표현하기 위한 도구이다. ER 다이어그램에는 ER 모델과 같이 개체 (entity), 속성 (property), 관계 (relationship)가 존재한다. 2. 구성 요소 ER 다이어그램을 구성하는 각 구성 요소들의 기호는 아래의 [그림 1]과 같다. [그림 1] ER 다이어그램의 구성 요소 및 기호 위의 [그림 1]에 나타낸 기호 이외에도 total participation은 double line으로, subtype과 supertype 관계는 supertype에서 subtype으로 향하는 화살표로 나타낸다. 3. ER 다이어그램의 변환 ER 다이어그램은 데이터베이스를 설계하.. 2016. 12. 10. [관계형 데이터베이스] - 데이터베이스 정규화 (Database Normalization) 1. 데이터베이스 정규화 관계형 데이터베이스의 설계 단계에서 데이터의 중복을 최소화하기 위해 데이터의 구조를 결정하는 작업을 정규화 (normalization)라고 한다. 일반적으로 데이터베이스 정규화 작업에서는 크고 제대로 조직되지 않은 테이블들과 테이블 간의 관계를 작고 잘 조직된 것으로 변경한다. 2. First Normal Form (1NF) 테이블에 존재하는 필드가 모두 scalar value만을 가지며, 필드의 값이 모두 atomic 할 때, 1NF라고 한다. 여기에서 atomic 하다는 것은 테이블에 중복되는 항목이 존재하지 않아야 한다는 것과 같다. 1NF에서 "중복되는 항목이 없다"에 대한 정의는 명확한 것이 아니기 때문에 1NF에 대한 정의 또한 여러 개가 존재할 수 있다. [그림 1].. 2016. 12. 9. [관계형 데이터베이스] - ER 모델 (Entity-Relationship Model) 1. 개요 ER 모델 (Entity-Relationship model)은 데이터베이스를 디자인 하기 위해 이용되는 모델링 기법으로, 데이터베이스에 대한 요구 사항을 그래픽적으로 표현하는 방법이다. ER 모델에서는 데이터베이스에 저장되는 데이터들을 추상화하여 나타내기 때문에 특정 DBMS 및 하드웨어에 독립적으로 데이터베이스의 구조를 나타낼 수 있다. 2. 개체 (Entity) ER 모델에서 개체는 개별적으로 구별될 수 있는 모든 것을 말한다. 예를 들어, 어떠한 회사의 직원 정보가 저장된 데이터베이스에서는 직원, 부서 등이 개체가 된다. 개체에는 weak entity와 regular entity가 있다. weak entity: 개체가 가진 속성들로는 개체를 고유하게 정의할 수 없는 개체를 말한다. 예를 .. 2016. 12. 7. [관계형 데이터베이스] - 함수 종속성 (Functional Dependency) 1. 함수 종속성 관계형 데이터베이스의 설계에서 중복된 데이터가 최소화되도록 데이터베이스의 구조를 결정하는 것을 정규화 (normalization)라고 한다. 정규화된 데이터베이스가 그렇지 않은 데이터베이스에 비하여 더욱 효율적으로 데이터에 대한 연산을 수행할 수 있는 것은 매우 당연한 것이다. 이러한 데이터베이스의 정규화 과정에서 함수 종속성이라는 개념은 매우 중요하게 이용된다.함수 종속성은 수학에서의 함수와 같이 두 필드의 집합이 many-to-one 관계로 사상되는 것을 말한다. 즉, 함수와 같이 어떠한 값을 통해 종속 관계에 있는 다른 값을 유일하게 결정할 수 있다는 것이다. 데이터베이스에서의 함수 종속성을 더욱 명확하게 정의하면 다음과 같다. 어떤 테이블 $R$에 존재하는 필드들의 부분집합을 각.. 2016. 11. 13. [관계형 데이터베이스] - 데이터베이스와 뷰 1. 뷰 (View)의 개념 뷰는 다른 테이블을 기반으로 만들어진 가상의 테이블을 의미한다. 뷰는 실제로 데이터를 저장하고 있지 않으며, 논리적으로만 존재한다. 그러나 데이터베이스 사용자는 실제로 데이터가 존재하는 테이블과 동일하게 뷰를 조작할 수 있다. SQL 기반의 데이터베이스에서는 뷰를 named table, derived table, virtual table이라고 말하기도 한다.아래의 [그림 1]은 department 테이블에서 생성된 두 개의 뷰를 보여준다. 하나의 뷰는 공과대학에 소속된 학과만을 포함하고 있으며, 다른 하나의 뷰는 상경대학에 소속된 학과만을 포함하고 있다. [그림 1] 뷰의 생성 데이터베이스 사용자는 [그림 1]과 같이 하나의 실제 데이터 (테이블)로부터 가상의 논리적 구조 (.. 2016. 11. 13. [관계형 데이터베이스] - 무결성 (Integrity) 1. 데이터의 무결성 데이터의 무결성은 데이터의 정확성, 일관성, 유효성이 유지되는 것을 말한다. 데이터의 무결성을 유지하는 것은 데이터베이스 관리시스템 (DBMS)의 중요한 기능이며, 주로 데이터에 적용되는 연산에 제한을 두어 데이터의 무결성을 유지한다. 데이터베이스에서 말하는 무결성에는 다음과 같은 4가지 종류가 있다. 1) 개체 무결성 (Entity integrity)모든 테이블이 기본 키 (primary key)로 선택된 필드 (column)를 가져야 한다. 기본 키로 선택된 필드는 고유한 값을 가져야 하며, 빈 값은 허용하지 않는다. 2) 참조 무결성 (Referential integrity)관계형 데이터베이스 모델에서 참조 무결성은 참조 관계에 있는 두 테이블의 데이터가 항상 일관된 값을 갖도.. 2016. 11. 13. 샘플링 (Sampling), 양자화 (Quantization) 및 부호화 (Coding) 1. 샘플링 (Sampling) 컴퓨터는 0과 1 같은 이산적인 자료들로 구성된다. 그러나 실세계에서는 0과 1사이에도 무한히 많은 수가 존재한다. 샘플링은 연속적인 시간에 대해 생성되는 데이터를 이산적인 시간에 대한 데이터로 변환하는 과정이다. [그림 1] 아날로그 데이터에 대한 샘플링 컴퓨터에서는 연속적인 시간에 대한 데이터에 포함되어 있는 무한히 많은 정보를 모두 저장할 수 없기 때문에 위의 [그림 1]과 같이 0, 1, 2, ... 와 같은 일정 시간 간격으로 데이터를 읽는 샘플링을 수행한다. 2. 양자화 (Quantizaton) 샘플링은 연속적인 시간에 대해 생성되는 데이터를 이산적인 시간에 대한 데이터로 변환하는 과정이다. 실세계의 아날로그 데이터는 시간뿐만 아니라, 데이터가 표현하는 값에 대.. 2016. 10. 24. 이전 1 2 3 4 5 6 7 8 ··· 13 다음