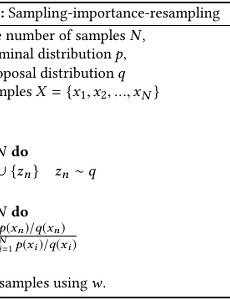지능형시스템25 [머신 러닝/딥 러닝] 인공신경망 (Artificial Neural Network, ANN)과 역전파 알고리즘 (Backpropagation Algorithm) Artificial neural network (ANN)는 딥 러닝의 가장 핵심적인 기술로써, 신경 세포인 neuron을 추상화한 artificial neuron으로 구성된 네트워크이다. ANN은 일반적으로 어떠한 형태의 function이든 근사할 수 있는 universal function approximator로도 알려져 있다. 이 글에서는 ANN을 구성하는 가장 작은 요소인 artificial neuron부터 multi-layer ANN과 이를 학습시키기 위한 algorithm에 대해 서술한다. 1. Neuron과 artificial neuronNeuron은 생물체의 신경계를 이루는 신경 세포를 말하며, artificial neuron은 생물체의 neuron을 구성하는 dendrite, soma, a.. 2018. 4. 21. [머신 러닝] 은닉 마르코프 모델 (Hidden Markov Model, HMM)의 개념과 학습 알고리즘 Markov model은 어떠한 날씨, 주식가격 등과 같은 어떠한 현상의 변화를 확률 모델로 표현한 것이다. Hidden Markov model (HMM)은 이러한 Markov model에 은닉된 state와 직접적으로 확인 가능한 observation을 추가하여 확장한 것이다. HMM은 observation을 이용하여 간접적으로 은닉된 state를 추론하기 위한 문제를 풀기 위해 사용된다. 아래의 [그림 1]은 은닉된 state와 그에 따른 observation의 개념을 나타낸다. HMM을 이용해 우리가 풀고자 하는 문제는 관측 가능한 것은 오직 $y_t$뿐이며, $y_t$는 $q_t$에 종속적으로 발생한다고 할 때, $y_t$의 sequence를 통해 $q_t$의 sequence를 추론하는 것이다. .. 2018. 4. 16. [머신 러닝/강화 학습] Markov Decision Process (MDP) 강화 학습은 주로 Markov decision process (MDP)라는 확률 모델로 표현된다. MDP는 의사결정 과정을 확률과 그래프를 이용하여 모델링한 것으로써, "시간 $t$에서의 상태는 $t-1$에서의 상태에만 영향을 받는다"는 first-order Markov assumption을 기반으로 고안되었다. First-order Markov assumption을 확률로 나타내면 식 (1)과 같다. $$p(s_t|s_0, s_1, ..., s_{t-1}) = p(s_t|s_{t-1}) \tag{1}$$ 이 글에서는 MDP에 대해 설명하기 전에 MDP의 기본 모델이 되는 Markov reward process에 대해 먼저 서술한다. 1. Markov reward process Markov reward .. 2018. 4. 11. [머신 러닝] 나이브 베이즈 분류기 (Naive Bayes Classifier, NBC) Naive Bayes Classifier (NBC)는 스팸 필터, 문서 분류 등에 사용되는 분류기이다. NBC의 기본 원리는 posterior probability에 베이즈 정리 (Bayes' theorem)과 naive한 가정을 적용하여 데이터를 분류하는 것이다. NBC는 1950년대 이후 광범위하게 연구되고 있으며, 적절한 전처리를 거치면 서포트 벡터 머신 (Support Vector Machine)과도 경쟁할 만큼 우수한 분류 성능을 보여준다. 1. Decision rule 먼저, state of nature $\omega_k \in \{0, 1 \}$를 정의한다. $\omega_k$는 $k$번째 class인 $c_k$가 선택되었을 때, 1의 값을 갖는 binary variable이다. NBC는 주.. 2018. 4. 10. [머신 러닝] Bayesian Decision Theory Bayesian decision theory는 통계 및 머신 러닝 분야에서 핵심적으로 이용되고 있는 방법론이다. Bayesian decision theory는 어떠한 decision problem이 확률적으로 표현이 가능하고, 해당 문제와 관련된 모든 확률값이 알려져 있다고 가정한다. 우리가 모든 확률을 알고 있을 때, 어떠한 사건에 대해 posterior probability를 비교하여 판단을 내리는 것이 Bayesian decision theory의 핵심적인 아이디어이다. 1. 기본적인 decision rule 우선 state of nature $\omega$를 정의한다. 만약, $\omega = \omega_k$라면 decision rule은 $k$번째 class를 선택한다. 우리는 직관적으로 [식.. 2018. 4. 8. [머신 러닝] 중요도 샘플링 (Importance Sampling)과 기댓값 추정 1. 중요도 샘플링 (Importance Sampling) 통계 및 머신러닝 방법론을 공부하다보면 어떠한 확률분포 $p(\textbf{x})$를 따르는 확률변수 $\textbf{x}$에 대해 함수 $f(\textbf{x})$의 기댓값 (expected value)을 구하는 경우를 많이 접한다. 중요도 샘플링은 샘플 $\textbf{x}$에 대한 확률 $p(\textbf{x})$은 쉽게 계산할 수 있지만, $p(\textbf{x})$에서 샘플을 생성하는 것은 어려울 때 사용하는 방법이다. 먼저 $p(\textbf{x})$에 대한 $f(\textbf{x})$의 기댓값은 아래와 같이 정의된다. $$\begin{equation} E_{p(\textbf{x})} [f(\textbf{x})] = \int f(\te.. 2018. 4. 8. [머신 러닝] 기각 샘플링 (Rejection Sampling) Rejection sampling (또는 acceptance-rejection method)은 어떠한 주어진 확률 분포에서 효율적으로 샘플을 생성하기 위해 많이 이용되는 알고리즘이다. 우리가 샘플을 추출하고자 하는 확률 분포 $p$에 대해 아래의 조건이 만족될 때, rejection sampling은 매우 효율적으로 이용될 수 있다. 주어진 확률 분포 $p$의 확률 밀도 함수 (probability density function, PDF)를 알고 있어야 한다.그러나 $p$에서 직접 샘플을 생성하는 것은 매우 어렵거나 불가능하다.따라서, rejection sampling은 확률 밀도 함수를 알고는 있지만, 그 함수를 통해 샘플을 생성하기가 어려울 때 활용할 수 있는 알고리즘이다. 1. 제안 분포 (Prop.. 2018. 4. 8. [데이터 마이닝] K-평균 군집화 (K-means Clustering)와 거리 기반 클러스터링 1. 알고리즘 정의 K-means clustering은 데이터를 입력받아 이를 소수의 그룹으로 묶는 알고리즘이다. 이 알고리즘은 아래의 [그림 1]처럼 label이 없는 데이터를 입력받아 각 데이터에 label을 할당함으로써 군집화를 수행한다. K-means clustering은 개념과 구현이 매우 간단한 기본적인 clustering 알고리즘이면서도 실행 속도가 빠르고, 특정한 형태의 데이터에 대해서는 매우 좋은 성능을 보여주기 때문에 많이 이용되고 있다. [그림 1] K-means clustering의 동작 K-means clustering은 벡터의 형태로 표현된 $N$개의 데이터 $X = \{x_1, x_,2, ..., x_N\}$에 대하여 데이터가 속한 cluster의 중심과 데이터 간의 거리의 차.. 2018. 4. 5. [최적화/전역 최적화] Tabu Search Tabu search는 simulated annealing, genetic algorithm 등과 같이 최적화 문제의 형태에 상관없이 주어진 최적화 문제를 풀기 위한 메타휴리스틱 (metaheuristic) 알고리즘이다. 기존의 simulated annealing, genetic algorithm과 같은 최적화 알고리즘들은 기본적으로 neighbor search를 기반으로 동작하기 때문에 current solution이 개선되는 방향으로만 진행하려는 성질이 있다. 이러한 성질로 인해 simulated annealing 및 genetic algorithm은 빈번하게 [그림 1]과 같은 지역 최적점 (local optimum)에 수렴한다. Tabu search는 빈번하게 지역 최적점에 수렴하는 문제를 해결하.. 2016. 9. 28. [수리적 최적화] 유전 알고리즘 (Genetic Algorithm)과 전역 최적화 1. 유전 알고리즘 (Genetic Algorithm) 소개 유전 알고리즘은 생물체가 환경에 적응하면서 진화해가는 모습을 모방하여 최적해를 찾아내는 최적화 방법이다. 유전 알고리즘은 이론적으로 전역 최적점을 찾을 수 있으며, 수학적으로 명확하게 정의되지 않은 문제에도 적용할 수 있기 때문에 다양한 응용에서 매우 활발히 이용되고 있다. 일반적으로 유전 알고리즘에 대해 알고리즘이라는 표현을 이용하지만, 유전 알고리즘은 특정한 문제를 풀기 위한 알고리즘이라기 보다는 최적화 문제를 풀기 위한 일반적인 방법론에 가깝다. 즉, 모든 문제에 적용 가능한 하나의 알고리즘이나 소스 코드가 있는 것이 아니기 때문에 유전 알고리즘의 원리를 이해하고, 이를 자신이 원하는 문제에 적용할 수 있도록 설계하는 것이 중요하다. 유전.. 2016. 9. 16. 라그랑주 승수법 (Lagrange Multiplier Method) 라그랑주 승수법 (Lagrange multiplier method)은 프랑스의 수학자 조세프루이 라그랑주 (Joseph-Louis Lagrange)가 제약 조건이 있는 최적화 문제를 풀기 위해 고안한 방법이다. 라그랑주 승수법은 어떠한 문제의 최적점을 찾는 것이 아니라, 최적점이 되기 위한 조건을 찾는 방법이다. 즉, 최적해의 필요조건을 찾는 방법이다. 1. 기하학적 해석 라그랑주 승수법의 기본 가정은 "제약 조건 $g$를 만족하는 $f$의 최솟값 또는 최댓값은 $f$와 $g$가 접하는 지점에 존재할 수도 있다."는 것이다. 아래의 [그림 1]은 제약 조건 $g(x, y) = c$를 만족하는 $f(x, y)$의 최댓값을 구하는 문제를 나타낸다. 만약, $f(x, y)$의 최댓값을 $k$라고 하면, $k$.. 2016. 9. 1. [머신러닝] - 단층 퍼셉트론(Single-layer Perceptron) 1. 개요 퍼셉트론은 1957년 코넬 항공 연구소(Cornell Aeronautical Lab)의 프랑크 로젠블라트(Frank Rosenblatt)에 의해 고안된 인공신경망이다. 로젠블라트에 의해 제안된 것은 가장 간단한 형태의 단층 퍼셉트론(single-layer perceptron)으로 입력 벡터를 두 부류로 구분하는 선형분류기이다. 2. 용어 정의 임계치(threshold): 어떠한 값이 활성화되기 위한 최소값을 임계치라고 한다. 가중치(weight): 퍼셉트론의 학습 목표는 학습 벡터를 두 부류로 선형 분류하기 위한 선형 경계를 찾는 것이다. 가중치는 이러한 선형 경계의 방향성 또는 형태를 나타내는 값이다. 바이어스(bias): 선형 경계의 절편을 나타내는 값으로써, 직선의 경우는 $y$절편을 나.. 2016. 2. 15. 이전 1 2 3 다음