Bayesian decision theory는 통계 및 머신 러닝 분야에서 핵심적으로 이용되고 있는 방법론이다. Bayesian decision theory는 어떠한 decision problem이 확률적으로 표현이 가능하고, 해당 문제와 관련된 모든 확률값이 알려져 있다고 가정한다. 우리가 모든 확률을 알고 있을 때, 어떠한 사건에 대해 posterior probability를 비교하여 판단을 내리는 것이 Bayesian decision theory의 핵심적인 아이디어이다.
우선 state of nature $\omega$를 정의한다. 만약, $\omega = \omega_k$라면 decision rule은 $k$번째 class를 선택한다. 우리는 직관적으로 [식 1]과 같이 모든 $\omega$에 대해 $P(\omega_k)$가 가장 크다면 $k$번째 class를 선택할 수 있다.

이는 매우 직관적이면서도 단순한 decision rule인데, 1년 중 비가 오는 날보다는 맑은 날이 많았기 때문에 항상 날씨가 맑을 것이라고 예상하는 것과 같다.

[식 1]에서 $P(\omega)$는 prior probability로써, "1년 중 비가 오는 날보다는 맑은 날이 많았다."라는 것과 같은 우리의 사전 지식을 반영한다. 만약, $P(\omega_1) = 0.9, P(\omega_2) = 0.1$이라면, 항상 첫 번째 클래스만 선택하여도 90%의 정확도를 보여줄 것이다. 그러나 $P(\omega_1) = 0.51, P(\omega_2) = 0.49$라면, 우리는 51%의 정확도를 얻는 것이 최대일 것이다.
위의 [식 1] 보다 더욱 정확한 decision rule은 데이터를 살펴본 뒤에 예측을 하는 것이다. 예를 들어, 오늘의 습도를 관측한 뒤에 날씨를 예측하는 것과 같다. 이러한 decision rule을 식으로 나타내면 아래의 [식 2]와 같이 posterior probability로 표현할 수 있다..

[식 2]에 베이즈 정리 (Bayes' theorem)을 적용하면, [식 3]과 같은 decision rule을 얻을 수 있다.

위의 [식 2] 또는 [식 3]과 같은 방식으로 결정을 내리는 것을 Bayes decision rule이라 한다.
Bayesian decision theory를 따라 판단을 내릴 때 발생하는 error는 [식 4]와 같이 확률적으로 표현될 수 있다.

[식 4]의 $P(error|x)$를 probability of error라고 하며, $C$는 class의 수이다. 이때 모든 데이터에 대한 probability of error는 [식 5]와 같이 표현된다.

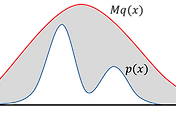
$P(error)$를 기하학적으로 표현하면 아래의 [그림 1]과 같다.

모든 데이터에 대해 $P(error|x)$가 최소화되면, $P(error)$ 또한 최소화되는 것은 매우 자명하다. Bayes decision rule은 [식 2]와 같이 항상 $P(\omega_k|x)$가 최대인 class를 선택하기 때문에 모든 데이터에 대해 $P(error|x)$가 최소화된다. 따라서, Bayes decision rule은 $P(error)$를 최소화하는 최적의 decision rule이다.
'지능형시스템 > 머신러닝' 카테고리의 다른 글
| [머신 러닝/강화 학습] Markov Decision Process (MDP) (0) | 2018.04.11 |
|---|---|
| [머신 러닝] 나이브 베이즈 분류기 (Naive Bayes Classifier, NBC) (0) | 2018.04.10 |
| [머신 러닝] 중요도 샘플링 (Importance Sampling)과 기댓값 추정 (4) | 2018.04.08 |
| [머신 러닝] 기각 샘플링 (Rejection Sampling) (0) | 2018.04.08 |
| [머신러닝] - 단층 퍼셉트론(Single-layer Perceptron) (15) | 2016.02.15 |