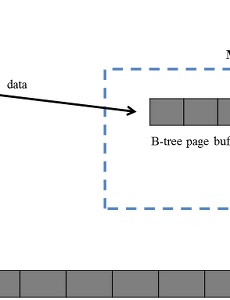
전체 글149 이진 탐색 트리(Binary Search Tree) 1. 개요 이진 탐색 트리(binary search tree)는 각 노드가 최대 2개의 child node를 갖는 이진 트리(binary tree)의 특수한 형태이다. 이진 탐색 트리는 데이터를 정렬된 형태로 보관하기 때문에 효율적으로 탐색 연산을 수행할 수 있다. 평균적으로 이진 탐색 트리에서 탐색 연산의 시간복잡도는 $O(\log_2n)$이다. 그러나 이진 탐색 트리는 입력되는 값의 순서에 따라 트리의 구성이 달라지기 때문에 트리가 한쪽으로 기울어진 편향 이진 트리(skewed binary tree)가 생성될 수 있다. 이러한 경우에는 탐색 연산의 시간복잡도가 $O(n)$으로 급증한다. 2. 정의 이진 탐색 트리의 정의는 아래와 같다. 각 노드는 최대 2개의 child node만을 가질 수 있다.노드.. 2016. 6. 25. 트리(Tree) 1. 개요 트리는 그래프의 한 종류로써, 유닉스 및 리눅스의 파일 시스템과 검색 엔진 등에서 널리 사용되고 있는 자료구조이다. 트리는 컴퓨터공학의 모든 자료구조 중에서도 가장 많은 변형이 있으며, 대부분의 경우에 배열(array)보다 유연하고 연결 리스트(linked list)보다 효율적이다. [그림 1] 트리 구조의 활용 위의 [그림 1]과 같이 트리의 개념은 컴퓨터공학뿐만 아니라 생명과학, 게임 등 다양한 분야에서 이용되고 있다. 2. 수학적 정의 트리의 개념을 이해하기 위해서는 먼저 이산 수학(discrete mathematics)의 그래프(graph)를 이해할 필요가 있다. 그래프 $G$는 $G = (V, E)$와 같이 표현되며, $V$는 그래프 내의 어떠한 지점을 가리키는 vertex의 집합이고.. 2016. 6. 25. 이중 연결 리스트(Doubly Linked List) 1. 개요 일반적인 연결 리스트(linked list)의 노드들은 다음 노드를 가리키는 포인터만 포함하고 있기 때문에 한 방향으로만 탐색이 가능하다. 그러나 이중 연결 리스트(doubly linked list)의 노드는 아래의 그림과 같이 next와 prev라는 두 개의 포인터를 포함하고 있다. 노드의 next 포인터는 일반적인 연결 리스트와 같이 다음 노드를 가리키며, 이중 연결 리스트의 노드에 추가된 prev 포인터는 이전 노드를 가리킨다. 이중 연결 리스트의 가장 큰 장점은 일반적인 연결 리스트에 비해 효율적으로 탐색할 수 있다는 점이다. 예를 들어, 노드의 수가 $n$인 일반적인 연결 리스트에서는 $n-1$번째 노드에 접근하기 위해, 총 $n-2$번의 포인터 추적이 필요하다. 그러나 이중 연결 리.. 2016. 6. 18. LinkedList.h Content: linked listLanguage: C++Official home page: noneDownload link: noneDownload file: 2016. 6. 17. 연결 리스트(Linked List) 1. 개요 선형 사상(sequential mapping)을 이용하는 배열, 큐와 같은 구조에서 insertion, deletion 연산은 매우 많은 비용이 소모된다. 아래의 그림은 배열에서 insertion 연산이 발생하는 경우, 연산이 실행되는 과정을 나타낸다. 선형 사상을 이용하는 배열과 같은 구조에서는 중간에 데이터를 추가하기 위해서는 해당 위치 다음에 저장된 모든 데이터를 일정 위치만큼씩 옮겨야한다. 이러한 shift 동작은 메모리 상에서도 많은 오버헤드가 발생하지만, 만약 하드디스크 상에서 shift 동작이 발생한다면 시스템이 감당할 수 없을 정도의 오버헤드가 발생할 수도 있다. 배열과 같은 선형 사상을 이용하는 구조의 또다른 문제점은 항상 고정된 크기를 갖기 때문에 예상한 것보다 데이터가 적게.. 2016. 6. 17. [파일구조] - B+ 트리 1. 개요 B+ 트리의 개념은 B 트리와 같다. 그러나 B 트리는 entry sequenced file을 이용하여 데이터 파일을 표현하지만, B+ 트리는 indexed sequential file을 이용한다. Indexed sequential file의 장점과 구현 방법은 이전의 글에서 설명하였다. B+ 트리는 인덱스로 indexed sequential file의 separator를 이용한다. Indexed sequential file의 separator는 유일하게 결정되는 것이 아니라, 같은 파일이더라도 다양한 separator가 정의될 수 있으므로, B+ 트리의 개념을 설명하기 위해 실제 key 값의 가장 짧은 prefix를 separator로 이용하는 simple prefix B+ 트리를 예로 들어.. 2016. 6. 12. [파일구조] - Indexed Sequential File 1. 개요 B 트리에서 사용되는 entry sequenced file과 반대되는 것으로 indexed sequential file이 있다. Indexed sequential file은 인덱스를 통해 데이터 파일의 각 레코드에 접근할 수 있으며, 데이터 파일의 레코드가 정렬된 순서로 저장되어 있는 구조를 갖고 있다. Indexed sequential file은 인덱스를 통해 각 레코드에 접근할 수 있다는 점이 entry sequenced file과 같지만, 데이터 파일의 레코드가 정렬되어 있다는 점이 다르다. 그러나 데이터 파일을 정렬된 순서로 유지하는 것은 하드디스크 상에서 데이터가 삽입될 위치를 찾고, 그 뒤에 있는 데이터를 모두 shift 해야 하기 때문에 막대한 비용이 소모된다. Indexed se.. 2016. 6. 12. [파일구조] - Virtual B 트리 1. 개요 B 트리 구조를 이용하여 인덱스를 저장한 데이터 파일을 읽기 위해서는 항상 B 트리의 root node가 저장된 페이지를 하드디스크에서 읽어야 한다. 그러나 하드디스크에서 데이터를 읽는 것은 막대한 비용이 소모되기 때문에 파일 시스템의 성능을 저하시키는 요인으로 작용한다.이러한 문제를 해결하기 위해 B 트리의 root node가 저장된 페이지를 메모리에 유지하는 keep-the-root strategy가 고안되었다. Virtual B 트리는 keep-the-root-strategy를 확장하여 B 트리를 구성하는 정보가 저장된 몇 개의 페이지를 메모리 상의 버퍼에 저장하여 하디드스크 접근을 최소화하는 B 트리의 변형이다. 2. Page Replacement 알고리즘 Virtual B 트리는 제한.. 2016. 6. 12. [파일구조] - B 트리의 연산 1. Insert 연산 Insert 연산은 인자로 전달받은 key를 B 트리에 추가하는 연산으로써, B 트리의 insert 연산은 다른 종류의 트리에 비해 매우 복잡하다. B 트리의 insert 연산은 아래와 같은 과정으로 수행된다. 1) 새로운 key 값이 입력될 leaf node를 탐색한다. B 트리에서 leaf node를 탐색하는 과정은 이진 탐색 트리(binary search tree)에서 주어진 값에 대한 노드를 찾는 과정과 유사하다.2) 선택된 leaf node의 모든 key 값 중에서 새로운 key 값이 가장 크다면, 선택된 leaf node의 가장 큰 key 값에 대한 정보를 모두 새로운 key 값으로 변경한다. 이러한 변경은 B 트리 전체에서 발생한다.3) 새로운 key 값을 선택된 le.. 2016. 6. 12. [파일구조] - B 트리 1. 개요 B 트리는 대용량의 파일을 효율적으로 관리하기 위한 자료구조로써, 산업 분야에서 데이터베이스 시스템에 전반적으로 사용되고 있는 de facto 표준이다. 가끔 이진 탐색 트리(binary search tree)와 B 트리를 혼동하는 경우가 있는데, 두 종류의 트리는 완전히 다른 구조와 연산을 갖고 있다. 인덱스를 이용하는 파일 시스템에서 가장 큰 문제는 '어떻게 하면 메모리에 올릴 수 없을 정도로 큰 용량의 인덱스에 효율적으로 접근할 것인가?'이다. 파일 시스템에서 인덱스를 이용하는 가장 근본적인 이유는 파일 전체를 이진 탐색(binary search)하여 레코드를 찾는 것보다 인덱스를 이용하는 것이 더 빠르기 때문이다. 따라서, B 트리는 아래의 두 가지 요구사항을 반드시 충족해야 한다. 인.. 2016. 6. 11. [파일구조] - 트리 구조를 이용한 인덱스 관리 1. 트리 구조를 이용한 인덱스 관리 이전의 배열이나 inverted list를 이용한 인덱스 체계의 문제점을 극복하고자 인덱스를 트리 구조로 관리하는 것에 대한 많은 연구가 이루어졌다. 인덱스를 관리하기 위한 자료 구조를 고안할 때는 반드시 아래와 같은 사항을 고려해야 한다. 인덱스를 정렬된 상태로 유지할 수 있어야 하며, 인덱스를 정렬하는 비용을 최소화해야 한다.인덱스의 추가(insertion), 삭제(deletion)을 효율적으로 수행할 수 있어야 한다.인덱스를 효율적으로 검색할 수 있어야 한다.이러한 세 가지 요구 사항을 만족시킬 수 있는 자료 구조로는 이진 탐색 트리가 있다. 이진 탐색 트리는 아래의 그림과 같이 모든 데이터를 정렬된 상태로 보관하며, 각 노드는 2개 이하의 자식 노드만 가질 수.. 2016. 6. 11. [파일구조] - 인덱스 파일의 구현 II 이 글의 소스 코드는 File Structures: An Object-Oriented Approach with C++ 3rd Edition의 내용을 수정하여 작성한 것 입니다. 1. 인덱스 파일의 구조 인덱스 파일은 앞에서 정의한 TextIndex를 저장하는 파일이다. 인덱스 파일은 고정 길이 필드, 고정 길이 레코드로 구성된다. 인덱스 파일은 파일은 파일 자체를 나타내는 BufferFile과 메모리 상에 인덱스를 저장하고 있는 TextIndex, 그리고 TextIndex를 버퍼 단위로 파일입출력하기 위한 TextIndexBuffer로 구성된다. 2. Class TextIndexedFile TexIndexedFile은 데이터 파일만 하드디스크에 저장하는 것이 아니라, 인덱스 파일도 같이 저장한다. Tex.. 2016. 6. 10. 이전 1 ··· 5 6 7 8 9 10 11 ··· 13 다음