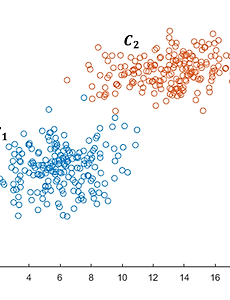
지능형시스템/데이터 마이닝3 [데이터 마이닝] DBSCAN과 밀도 기반 클러스터링 1. 밀도 기반 클러스터링 (Density-based clustering) 클러스터링 알고리즘은 크게 중심 기반 (center-based) 알고리즘과 밀도 기반 (density-based) 알고리즘으로 나눌 수 있다. 중심 기반 알고리즘의 가장 대표적인 것으로는 k-means clustering이 있으며, 밀도 기반 알고리즘에는 DBSCAN$^{[1]}$이 있다. 중심 기반 클러스터링 알고리즘은 "동일한 클래스에 속하는 데이터는 어떠한 중심을 기준으로 분포할 것이다"라는 가정을 기반으로 한다. 이와 다르게 밀도 기반 알고리즘은 "동일한 클래스에 속하는 데이터는 서로 근접하게 분포할 것이다"라는 가정을 기반으로 동작한다. 아래의 [그림 1]은 중심 기반 클러스터링 알고리즘 (k-means clusterin.. 2018. 9. 10. [데이터 마이닝] 주성분 분석 (Principal Component Analysis, PCA)과 차원 축소 1. 차원 축소 (Dimensionality reduction) 대부분의 경우, 현실 세계의 문제는 가공되지 않은 데이터를 처리해야 한다. 예를 들어, 머신 러닝 모델을 이용하여 증명사진에 있는 인물의 성별을 맞추는 문제가 있을 때, 이 문제를 풀기 위해 우리는 성별이 표시된 증명사진을 머신 러닝 모델의 학습 데이터로 이용할 것이다. 하나의 사진이 200X200의 이미지라고 하면, 해당 사진은 총 40,000개의 feature를 갖는 벡터로 표현이 될 것이다. 그러나 대부분의 머신 러닝 모델은 입력 데이터의 차원이 클 경우, 차원의 저주와 학습 속도가 저하되는 문제를 갖고 있다. 이를 위해 생각해볼 수 있는 것은 이미지에서 인물에 대한 정보를 포함하지 않는 부분을 제거하여 입력 데이터의 차원을 낮추는 것.. 2018. 8. 27. [데이터 마이닝] K-평균 군집화 (K-means Clustering)와 거리 기반 클러스터링 1. 알고리즘 정의 K-means clustering은 데이터를 입력받아 이를 소수의 그룹으로 묶는 알고리즘이다. 이 알고리즘은 아래의 [그림 1]처럼 label이 없는 데이터를 입력받아 각 데이터에 label을 할당함으로써 군집화를 수행한다. K-means clustering은 개념과 구현이 매우 간단한 기본적인 clustering 알고리즘이면서도 실행 속도가 빠르고, 특정한 형태의 데이터에 대해서는 매우 좋은 성능을 보여주기 때문에 많이 이용되고 있다. [그림 1] K-means clustering의 동작 K-means clustering은 벡터의 형태로 표현된 $N$개의 데이터 $X = \{x_1, x_,2, ..., x_N\}$에 대하여 데이터가 속한 cluster의 중심과 데이터 간의 거리의 차.. 2018. 4. 5. 이전 1 다음