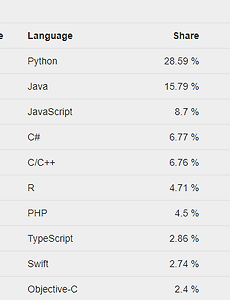
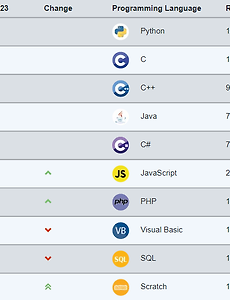
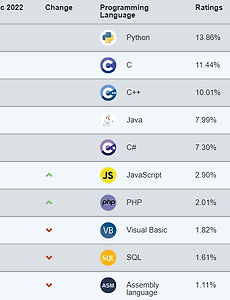
전체 글149 2024년 3월 최신 프로그래밍 언어 순위 1. 2024년 3월 TIOBE Index TIOBE Index는 가장 많이 이용되는 프로그래밍 언어 순위표 중 하나이다. TIOBE Index에서는 아래의 3가지 지표를 기반으로 프로그래밍 언어의 순위를 설정한다. 해당 프로그래밍 언어를 이용하는 엔지니어의 수: 과거에 프로그래밍 언어를 배웠던 엔지니어들도 포함되기 때문에 이 수치는 프로그래밍 언어의 과거부터 현재까지의 인기를 간접적으로 포함한다. 해당 프로그래밍 언어 관련 강좌 및 홈페이지의 수: 일반적으로 프로그래밍 관련 강좌에서는 프로그래밍과 관련된 개념을 설명하기 위해 C와 Java처럼 전통적인 언어를 자주 다루기 때문에 TIOBE Index에서는 전통적인 프로그래밍 언어의 순위가 높게 설정되는 경향이 있다. Google, Bing, Wikipe.. 2024. 3. 20. 2024년 2월 최신 프로그래밍 언어 순위 1. 2024년 2월 TIOBE Index TIOBE Index는 아래의 3가지 지표를 기반으로 프로그래밍 언어의 순위를 설정한다. 해당 프로그래밍 언어를 이용하는 엔지니어의 수: 과거에 프로그래밍 언어를 배웠던 엔지니어들도 포함되기 때문에 이 수치는 프로그래밍 언어의 과거부터 현재까지의 인기를 간접적으로 포함한다. 해당 프로그래밍 언어 관련 강좌 및 홈페이지의 수: 일반적으로 프로그래밍 관련 강좌에서는 프로그래밍과 관련된 개념을 설명하기 위해 C와 Java처럼 전통적인 언어를 자주 다루기 때문에 TIOBE Index에서는 전통적인 프로그래밍 언어의 순위가 높게 설정되는 경향이 있다. Google, Bing, Wikipedia 등에서 프로그래밍 언어가 검색된 횟수: 인터넷 검색량을 기반으로 계산되기 때문.. 2024. 2. 29. 편향-분산 트레이드오프 (Bias-Variance Tradeoff)와 L2 규제 (L2 Regularization) 1. 예측 모델의 편향 (Bias)과 분산 (Variance) 어떠한 학습 문제에서 아래와 같은 두 학생 A와 B를 생각해볼 수 있다. 학생 A: 고집이 너무 강해서 아무리 새로운 지식을 학습을 시켜도 자신의 주관대로 판단하는 성격 학생 B: 귀가 너무 얇아서 옳은 것이든 틀린 것이든 학습시키는 그대로 수용하는 성격 위의 예시를 머신러닝 문제에서 생각해보면 A는 편향이 크고 분산은 작은 예측 모델이며, 대표적으로 선형회귀 (linear regression)와 같은 모델이 있다. 반면에 B는 편향은 작지만 분산이 큰 예측 모델이며, 대표적으로 고차 다항 회귀 (high-degree polynomial regression)나 심층 인공신경망 (deep neural network) 등이 있다. 선형회귀와 같이.. 2024. 1. 15. 2024년 1월 최신 프로그래밍 언어 순위 1. 2024년 1월 TIOBE Index TIOBE Index는 아래의 3가지 지표를 주로 반영하여 프로그래밍 언어의 순위를 설정한다. 해당 프로그래밍 언어를 이용하는 엔지니어의 수: 과거에 프로그래밍 언어를 배웠던 엔지니어들도 포함되기 때문에 이 수치는 프로그래밍 언어의 과거부터 현재까지의 인기를 간접적으로 포함한다. 해당 프로그래밍 언어 관련 강좌 및 홈페이지의 수: 일반적으로 프로그래밍 관련 강좌에서는 프로그래밍과 관련된 개념을 설명하기 위해 C와 Java처럼 전통적인 언어를 자주 다루기 때문에 TIOBE Index에서는 전통적인 프로그래밍 언어의 순위가 높게 설정되는 경향이 있다. Google, Bing, Wikipedia 등에서 프로그래밍 언어가 검색된 횟수: 인터넷 검색량을 기반으로 계산되기.. 2024. 1. 15. Unbiased and Biased Estimators의 개념과 머신러닝 1. Unbiased and Biased Estimators 확률모델의 학습에서 우리의 목적은 주어진 샘플 (데이터) $\textbf{x}_1, \textbf{x}_2, ..., \textbf{x}_n$으로부터 데이터를 생성한 확률분포 $p(\textbf{x}|\theta)$의 참된 매개변수 $\theta$를 찾는 것이다. 그러나 대부분의 머신러닝 응용에서는 모든 데이터를 관측할 수 없기 때문에 추정된 매개변수 $\tilde{\theta}$는 참된 매개변수 $\theta$와 차이가 있을 것이다. 통계학에서 편향 (bias)은 추정된 매개변수와 참된 매개변수의 차이를 말하며, 편향은 추정된 매개변수의 기댓값을 기반으로 식 $\eqref{eq:bias}$과 같이 정의된다. $$\begin{equation} .. 2024. 1. 11. 몬테카를로 방법 (Monte Carlo Method)과 베이지안 머신러닝 1. 큰 수의 법칙 (Law of Large Numbers, LLN) 이 글에서 소개할 몬테카를로 방법 (Monte Carlo method)은 큰 수의 법칙을 기반으로 하며, 큰 수의 (약한) 법칙은 동일한 확률분포에서 독립적으로 추출된 (i.i.d. 조건) 확률변수에 대해 아래와 같이 정의된다. i.i.d. 확률변수 $X_1, X_2, ..., X_n$에 대해 $n$ 증가하면 $\bar{X} = \frac{X_1 + X_2 + \cdots + X_n}{n}$은 실제 기댓값 $\mu$로 수렴한다. 큰 수의 법칙은 샘플 (데이터)이 생성된 확률분포를 모르더라도 샘플로부터 확률분포에 대한 정보를 추정할 수 있음을 보여준다. 이러한 큰 수의 법칙을 직관적으로 나타내면 식 $\eqref{eq:lln}$과 같다... 2024. 1. 7. 2023년 12월 최신 프로그래밍 언어 순위 1. 2023년 12월 TIOBE Index TIOBE Index는 아래의 3가지 지표를 주로 반영하여 프로그래밍 언어의 순위를 설정한다. 해당 프로그래밍 언어를 이용하는 엔지니어의 수: 과거에 프로그래밍 언어를 배웠던 엔지니어들도 포함되기 때문에 이 수치는 프로그래밍 언어의 과거부터 현재까지의 인기를 간접적으로 포함한다. 해당 프로그래밍 언어 관련 강좌 및 홈페이지의 수: 일반적으로 프로그래밍 관련 강좌에서는 프로그래밍과 관련된 개념을 설명하기 위해 C와 Java처럼 전통적인 언어를 자주 다루기 때문에 TIOBE Index에서는 전통적인 프로그래밍 언어의 순위가 높게 설정되는 경향이 있다.. Google, Bing, Wikipedia 등에서 프로그래밍 언어가 검색된 횟수: 인터넷 검색량을 기반으로 계산.. 2023. 12. 30. [머신러닝] 가우시안 혼합 모델 (Gaussian Mixture Model, GMM)과 EM 알고리즘 1. 가우시안 혼합 모델의 개념Gaussian Mixture Model (GMM)은 이름 그대로 가우시안 분포 (정규분포)를 여러 개 혼합하여 데이터의 복잡한 분포를 근사하기 위한 머신러닝 알고리즘이다. GMM은 그림 1과 같이 $K$개의 가우시안 분포를 혼합하여 복잡한 형태의 확률분포를 근사한다. $K$는 몇 개의 가우시안 분포를 혼합할 것인지를 결정하는 GMM의 hyperparameter이며, 그림 1은 $K=3$으로 설정된 GMM을 나타낸다.GMM에서 주어진 데이터 $\textbf{x}$가 발생할 확률은 아래의 식 $\eqref{eq:gmm}$과 같이 $K$개의 가우시안 확률밀도함수 (probability density function)의 혼합으로 정의된다.$$\begin{equation} p(\t.. 2023. 12. 29. Reparameterization Trick에 대한 수학적 이해와 기댓값의 미분가능성 1. 기댓값 (Expectation)의 미분가능성 많은 머신러닝 문제에서 우리는 식 (1)과 같이 모델 매개변수 $\theta$에 대해 어떠한 기댓값을 최대화하고자 한다. $$ \theta^* = \underset{\theta}{\text{argmax}} \; E_{p(x)}[f_{\theta}(x)]. \tag{1} $$ 식 (1)을 풀기 위해 $\theta$에 대해 $E_{p(x)}[f_{\theta}(x)]$를 미분하면 다음과 같다. $$\begin{align*}\nabla_{\theta} E_{p(x)}[f_{\theta}(x)] &= \nabla_{\theta} \left[ \int_x p(x) f_{\theta}(x) dx \right]\\ &= \int_x p(x) \left[\nabla_{.. 2023. 12. 21. 파이썬 RDKit을 이용한 분자 유사도 (Tanimoto Similarity) 계산 1. Tanimoto 유사도 분자 유사도 계산을 위해서는 분자의 표현 방식과 유사도 계산 방법을 정해야한다. 분자의 표현 방식에는 그림 1과 같이 fingerprint, 이미지, 그래프 등이 있다. 분자 유사도 계산 방법에는 그래프 유사도, dice 유사도, Tanimoto 유사도 등이 있다. Tanimoto 유사도는 주로 0과 1의 나열로 분자를 표현한 fingerprint에 이용되며, $M_1$과 $M_2$라는 분자 표현에 대해 아래의 식 (1)과 같이 정의된다. $$\begin{equation} \mathcal{T}(M_1, M_2) = \frac{|M_1 \cap M_2|}{|M_1 \cup M_2|} = \frac{|M_1 \cap M_2|}{|M_1| + |M_2| - |M_1 \cap M_2.. 2023. 12. 19. Conjugate Prior의 정의와 예제 1. Conjugate Prior의 정의 베이지안 머신러닝 (Bayesian machine learning)에서는 주어진 데이터셋 $\mathcal{D}$에 대해 모델 매개변수 $\theta$의 사후 확률 (posterior probability) $p(\theta|\mathcal{D})$를 최대화하도록 모델 학습이 진행된다. 이를 식으로 나타내면 아래와 같다. $$\begin{align*} \theta^* &= \underset{\theta}{\text{argmax}} \; p(\theta|\mathcal{D})\\ &= \underset{\theta}{\text{argmax}} \; p(\mathcal{D}|\theta) p(\theta) \tag{1} \end{align*}$$ Conjugate p.. 2023. 12. 18. 선형회귀 (Linear Regression)에 대한 여러 접근법 1. 선형회귀 (Linear Regression) 선형회귀는 입력 $\textbf{x} \in \mathbb{R}^{d \times 1}$와 출력 $y \in \mathbb{R}$를 식 (1)과 같은 선형 관계로 모델링하기 위한 회귀분석이다. $$\begin{equation} y = \textbf{w}_1 \textbf{x}_1 + ... \textbf{w}_d \textbf{x}_d + b = \textbf{w}^T \textbf{x} + b \tag{1} \end{equation}$$ 위의 식에서 $\textbf{w} \in \mathbb{R}^{d \times 1}$와 $b \in \mathbb{R}$는 선형회귀 모델의 매개변수이다. $N$개의 데이터를 포함하는 데이터셋 $\mathcal{D} = .. 2023. 12. 9. 이전 1 2 3 4 ··· 13 다음