B 트리에서 사용되는 entry sequenced file과 반대되는 것으로 indexed sequential file이 있다. Indexed sequential file은 인덱스를 통해 데이터 파일의 각 레코드에 접근할 수 있으며, 데이터 파일의 레코드가 정렬된 순서로 저장되어 있는 구조를 갖고 있다. Indexed sequential file은 인덱스를 통해 각 레코드에 접근할 수 있다는 점이 entry sequenced file과 같지만, 데이터 파일의 레코드가 정렬되어 있다는 점이 다르다.
그러나 데이터 파일을 정렬된 순서로 유지하는 것은 하드디스크 상에서 데이터가 삽입될 위치를 찾고, 그 뒤에 있는 데이터를 모두 shift 해야 하기 때문에 막대한 비용이 소모된다. Indexed sequential file에서는 데이터 파일을 정렬하는 비용을 줄이기 위해 sequence set이라는 개념을 이용한다. Sequence set의 정의는 다음과 같다.
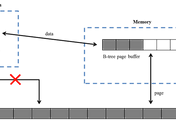
Block은 sequenced set과 같은 개념으로써, 고정된 수의 레코드를 저장할 수 있는 집합이다. Block을 이용하여 insertion과 deletion에 의해 발생하는 변화를 block 내에서만 발생하도록 국한시킬 수 있다.
앞에서 서술한 바와 같이 block은 key 값의 순서에 따라 실제 물리적 위치가 정렬되어 있는 레코드들의 집합이다. 즉, block 내부에 저장된 레코드들은 key 값의 순서에 따라 물리적으로 정렬되어 있지만, block 간에는 정렬 하지 않는다.
Block은 고정된 수의 레코드만을 저장할 수 있기 때문에 overflow가 발생하는 경우에는 한 block을 두 개의 block으로 분리해야 한다. 아래의 그림은 block에서 overflow가 발생한 상황과 overflow를 처리하기 위해 block을 분리하는 과정을 나타낸다.

반대로 block에서 레코드가 삭제되어 underflow가 발생하는 경우에는 두 block을 병합하거나 block에 저장된 레코드를 재배치한다.
Block의 크기를 설정할 때는 다음의 두 가지 사항을 고려해야 한다.
- Block은 split, merging이 발생할 수 있기 때문에 최소 2개 이상의 block을 메모리에 적재할 수 있어야 한다.
- 하나의 block을 읽을 때, 추가적인 seek가 발생하지 않아야 한다.
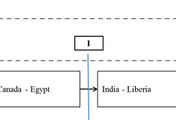
B 트리에서 인덱스는 각 레코드를 가리키는 포인터로 이용되었다. 그러나 block 단위로 레코드를 관리하는 indexed sequential file에서는 각 레코드마다 해당되는 인덱스를 유지하는 것이 아니라, 각 block을 구분하기 위한 separator를 이용한다. 아래의 그림은 separator를 이용하는 indexed sequential file의 구조를 나타낸다.

Separator는 이전 block의 마지막 레코드와 다음 block의 처음 레코드를 구분할 수 있는 적절한 값으로 설정되어야 한다. 또한, separator는 인덱스 구조에서 지원하는 크기 이내에서 가변적으로 설정될 수 있다.
'객체지향설계' 카테고리의 다른 글
| [파일구조] - B+ 트리 (8) | 2016.06.12 |
|---|---|
| [파일구조] - Virtual B 트리 (0) | 2016.06.12 |
| [파일구조] - B 트리의 연산 (0) | 2016.06.12 |
| [파일구조] - B 트리 (0) | 2016.06.11 |
| [파일구조] - 트리 구조를 이용한 인덱스 관리 (0) | 2016.06.11 |