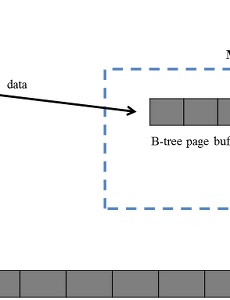
객체지향설계20 [파일구조] - B+ 트리 1. 개요 B+ 트리의 개념은 B 트리와 같다. 그러나 B 트리는 entry sequenced file을 이용하여 데이터 파일을 표현하지만, B+ 트리는 indexed sequential file을 이용한다. Indexed sequential file의 장점과 구현 방법은 이전의 글에서 설명하였다. B+ 트리는 인덱스로 indexed sequential file의 separator를 이용한다. Indexed sequential file의 separator는 유일하게 결정되는 것이 아니라, 같은 파일이더라도 다양한 separator가 정의될 수 있으므로, B+ 트리의 개념을 설명하기 위해 실제 key 값의 가장 짧은 prefix를 separator로 이용하는 simple prefix B+ 트리를 예로 들어.. 2016. 6. 12. [파일구조] - Indexed Sequential File 1. 개요 B 트리에서 사용되는 entry sequenced file과 반대되는 것으로 indexed sequential file이 있다. Indexed sequential file은 인덱스를 통해 데이터 파일의 각 레코드에 접근할 수 있으며, 데이터 파일의 레코드가 정렬된 순서로 저장되어 있는 구조를 갖고 있다. Indexed sequential file은 인덱스를 통해 각 레코드에 접근할 수 있다는 점이 entry sequenced file과 같지만, 데이터 파일의 레코드가 정렬되어 있다는 점이 다르다. 그러나 데이터 파일을 정렬된 순서로 유지하는 것은 하드디스크 상에서 데이터가 삽입될 위치를 찾고, 그 뒤에 있는 데이터를 모두 shift 해야 하기 때문에 막대한 비용이 소모된다. Indexed se.. 2016. 6. 12. [파일구조] - Virtual B 트리 1. 개요 B 트리 구조를 이용하여 인덱스를 저장한 데이터 파일을 읽기 위해서는 항상 B 트리의 root node가 저장된 페이지를 하드디스크에서 읽어야 한다. 그러나 하드디스크에서 데이터를 읽는 것은 막대한 비용이 소모되기 때문에 파일 시스템의 성능을 저하시키는 요인으로 작용한다.이러한 문제를 해결하기 위해 B 트리의 root node가 저장된 페이지를 메모리에 유지하는 keep-the-root strategy가 고안되었다. Virtual B 트리는 keep-the-root-strategy를 확장하여 B 트리를 구성하는 정보가 저장된 몇 개의 페이지를 메모리 상의 버퍼에 저장하여 하디드스크 접근을 최소화하는 B 트리의 변형이다. 2. Page Replacement 알고리즘 Virtual B 트리는 제한.. 2016. 6. 12. [파일구조] - B 트리의 연산 1. Insert 연산 Insert 연산은 인자로 전달받은 key를 B 트리에 추가하는 연산으로써, B 트리의 insert 연산은 다른 종류의 트리에 비해 매우 복잡하다. B 트리의 insert 연산은 아래와 같은 과정으로 수행된다. 1) 새로운 key 값이 입력될 leaf node를 탐색한다. B 트리에서 leaf node를 탐색하는 과정은 이진 탐색 트리(binary search tree)에서 주어진 값에 대한 노드를 찾는 과정과 유사하다.2) 선택된 leaf node의 모든 key 값 중에서 새로운 key 값이 가장 크다면, 선택된 leaf node의 가장 큰 key 값에 대한 정보를 모두 새로운 key 값으로 변경한다. 이러한 변경은 B 트리 전체에서 발생한다.3) 새로운 key 값을 선택된 le.. 2016. 6. 12. [파일구조] - B 트리 1. 개요 B 트리는 대용량의 파일을 효율적으로 관리하기 위한 자료구조로써, 산업 분야에서 데이터베이스 시스템에 전반적으로 사용되고 있는 de facto 표준이다. 가끔 이진 탐색 트리(binary search tree)와 B 트리를 혼동하는 경우가 있는데, 두 종류의 트리는 완전히 다른 구조와 연산을 갖고 있다. 인덱스를 이용하는 파일 시스템에서 가장 큰 문제는 '어떻게 하면 메모리에 올릴 수 없을 정도로 큰 용량의 인덱스에 효율적으로 접근할 것인가?'이다. 파일 시스템에서 인덱스를 이용하는 가장 근본적인 이유는 파일 전체를 이진 탐색(binary search)하여 레코드를 찾는 것보다 인덱스를 이용하는 것이 더 빠르기 때문이다. 따라서, B 트리는 아래의 두 가지 요구사항을 반드시 충족해야 한다. 인.. 2016. 6. 11. [파일구조] - 트리 구조를 이용한 인덱스 관리 1. 트리 구조를 이용한 인덱스 관리 이전의 배열이나 inverted list를 이용한 인덱스 체계의 문제점을 극복하고자 인덱스를 트리 구조로 관리하는 것에 대한 많은 연구가 이루어졌다. 인덱스를 관리하기 위한 자료 구조를 고안할 때는 반드시 아래와 같은 사항을 고려해야 한다. 인덱스를 정렬된 상태로 유지할 수 있어야 하며, 인덱스를 정렬하는 비용을 최소화해야 한다.인덱스의 추가(insertion), 삭제(deletion)을 효율적으로 수행할 수 있어야 한다.인덱스를 효율적으로 검색할 수 있어야 한다.이러한 세 가지 요구 사항을 만족시킬 수 있는 자료 구조로는 이진 탐색 트리가 있다. 이진 탐색 트리는 아래의 그림과 같이 모든 데이터를 정렬된 상태로 보관하며, 각 노드는 2개 이하의 자식 노드만 가질 수.. 2016. 6. 11. [파일구조] - 인덱스 파일의 구현 II 이 글의 소스 코드는 File Structures: An Object-Oriented Approach with C++ 3rd Edition의 내용을 수정하여 작성한 것 입니다. 1. 인덱스 파일의 구조 인덱스 파일은 앞에서 정의한 TextIndex를 저장하는 파일이다. 인덱스 파일은 고정 길이 필드, 고정 길이 레코드로 구성된다. 인덱스 파일은 파일은 파일 자체를 나타내는 BufferFile과 메모리 상에 인덱스를 저장하고 있는 TextIndex, 그리고 TextIndex를 버퍼 단위로 파일입출력하기 위한 TextIndexBuffer로 구성된다. 2. Class TextIndexedFile TexIndexedFile은 데이터 파일만 하드디스크에 저장하는 것이 아니라, 인덱스 파일도 같이 저장한다. Tex.. 2016. 6. 10. [파일구조] - 인덱스 파일의 구현 I 이 글의 소스 코드는 File Structures: An Object-Oriented Approach with C++ 3rd Edition의 내용을 수정하여 작성한 것 입니다. 1. Class TextIndex 인덱스 파일을 구현하기에 앞서, TextIndex라는 인덱스를 저장하는 자료구조를 정의한다. TextIndex는 일정 수의 인덱스들을 저장하는 자료구조로써, 인덱스의 추가, 제거, 검색 등의 연산을 갖는다. TextIndex의 class 정의는 아래와 같다. class TextIndex { public: TextIndex(int maxKeys = 100, bool unique = true); ~TextIndex(); int Insert(const char *key, int recAddr); int.. 2016. 6. 10. [파일구조] - 인덱싱(Indexing) 1. Entry Sequenced File Entry sequenced file은 레코드가 입력되는 순서대로 저장되는 파일이다. 레코드가 입력되는 순서대로 파일에 저장되기 때문에 파일에 저장된 레코드들은 정렬되어있지 않다. 파일에 저장된 레코드들이 정렬되어있지 않기 때문에 어떤 레코드를 찾기 위해서는 파일의 앞쪽부터 순차적으로 레코드를 읽어야한다. Entry sequenced file은 데이터를 관리한다는 측면에서는 매우 비효율적인 구조이다. Entry sequenced file의 이러한 문제점을 해결하기 위해 레코드가 입력될 때마다 레코드들을 정렬하는 sorted file을 생각할 수 있지만, sorted file에는 아래와 같은 치명적인 문제점이 존재한다. 레코드가 입력될 때 파일을 정렬한다면, 레코.. 2016. 6. 8. [파일구조] - 레코드 검색 1. 순차 탐색(Sequential Search)과 이진 탐색(Binary Search) 검색은 파일에서 가장 빈번하게 발생하는 연산이다. 따라서, 파일구조를 설계할 때는 파일 검색 연산을 신중히 구현해야 한다. 파일을 검색하기 위한 방법에는 크게 순차 탐색(sequential search)과 이진 탐색(binary search)이 있다. 순차 탐색의 시간 복잡도는 $O(n)$이며, 이진 탐색 트리에서 이진 탐색을 수행할 때의 시간 복잡도는 $log_2(n)$이다.일반적으로 순차 탐색보다 이진 탐색의 효율이 더 좋지만 이진 탐색은 데이터가 정렬되어 있어야 한다는 제약 조건이 존재한다. 또한, 가변 길이 레코드 파일에서 이진 탐색을 수행하기 위해서는 파일의 중간 지점을 찾는 방법에 대한 구현도 필요하다. .. 2016. 4. 24. [파일구조] - 레코드 관리 1. 레코드 삭제 파일을 이용하다보면 특정 레코드를 삭제하는 경우가 발생한다. 만약 삭제된 레코드가 파일의 가장 끝에 있는 레코드가 아니라면, 삭제된 레코드가 있었던 공간을 재사용하기 위한 방법이 필요하다. 레코드가 있었던 공간을 재사용하기 위해서는 가장 먼저 삭제된 레코드가 어디에 있었는지를 알고 있어야 한다. 2. Available List Available list는 파일에서 사용 가능한 공간을 저장하고 있는 데이터 집합이다. Available list는 스택(stack), 연결 리스트(linked list) 등의 자료구조를 이용하여 구현할 수 있다. 파일구조에서 available list의 구현에 대한 고려사항은 available list의 저장 위치이다. Available list를 저장할 수 .. 2016. 4. 24. [파일구조] - 레코드 접근과 성능 1. 순차 접근(Sequential Access) 원하는 레코드를 찾기 위해 파일의 현재 위치에서 차례대로 탐색을 실시하는 접근 방법이다. 특별한 구현이 없다면, 레코드를 접근할 때마다 디스크를 물리적으로 움직여야하기 때문에 매우 비효율적이다.순차 접근의 비효율성을 줄이기 위해 레코드 블록화(record blocking) 기법을 이용한다. 블록(block)은 여러 레코드의 집합이며, 파일 시스템은 레코드를 하나씩 읽어 메모리에 적재하는 것이 아니라 디스크에서 블록 단위로 데이터를 읽어 메모리에 적재한다. 예를 들어, 4,000개의 레코드로 구성된 파일을 블록 크기 16인 파일 시스템이 모두 읽기 위해서는 250번의 디스크 접근만 수행하면 된다. 레코드 블록화 기법에서 블록의 크기가 커지면 커질수록 디스크.. 2016. 4. 24. 이전 1 2 다음